site_replication Data Exists
Web Site Replication
In 1998, I was put in technical control of a site with several hundred thousand daily viewers. Over the following years,
it grew to have several million daily viewers. This number fluctuated between approximately 2 million to 8 million daily.
There was also another related site with well over 100,000 daily viewers.
Before being put in technical control, work was done on the webmasters workstations, and uploaded to the servers.
At the time, there were only approximately 3 servers handling the site, which were always heavily loaded. Due to
human error, the servers would frequently not have the same content on them.
I established a new updating hierarchy. When work was ready to be published, it was put onto an internal staging
server. The webmasters were instructed to add images at least one hour before new HTML, to ensure no broken
images were shown to the end users.
The webmasters were told that changes must be uploaded by 45 past the top of the hour. A cron'd even pushed
the changes out to the 5 servers of the largest site, and 3 servers on the smaller site. In reality, the update ran
at 0, 15, 30, 45, and 55. We found the webmasters would always push their limits, and frequently do large updates
at 55 minutes past the top of the hour.
In time, as traffic grew, the need for more servers increased also. Through optimal tuning of the servers, it was not a
matter of how much load the machine could take, but how much traffic an interface could pass. The servers themselves
had two 100baseTX interfaces bound together to allow for 200Mb/s outbound traffic, and had been tested to be able to
exceed 150Mb/s before memory limitations became a problem. The count of servers grew to 15 for the main site,
and 6 for the smaller site. The servers were housed in diverse physical locations to avoid problems with a particular datacenter,
or the occasional problem with a city. We maintained that any one server could go down, and not require attention. Any one
city could become disabled, and traffic would need to be redirected to the other cities.
When the number of servers grew so large, an external staging server was added to the equation, to avoid saturating the line
where the internal staging server resided. This happened frequently, when webmasters would drop huge updates in trying to
rush to finish work. It would take an unacceptable amount of time to update over 20 servers with several gigs of data across a
T1 in a very short time.
The final solution, which ran for many years was as shown in the graph below.
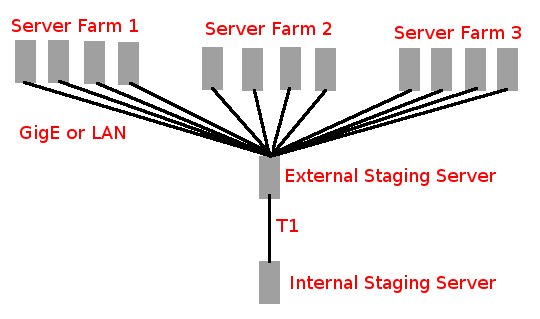
Site files were replicated from the Internal Staging server on a T1, to the External Staging server on a GigE circuit.
The External Staging Server would be able to synchronize much faster to the live web servers, which were handled simultaneously,
bringing the site data up to date very quickly. The External to Live servers synchronized at 0, 5, 20, 35, and 50. This reduced any
instant load, induced by the webmasters trying too hard to get too much work done at once.
The synchronization was handled with rsync, wrapped in a custom script to avoid unintentional errors, such as accidentally deleting the
entire site, or introducing malware through the web pages.
In the event of a failure of the external staging server, The files could be copied back down from a server on it's LAN. It could also be reassigned
to any other standby server as needed.
In the event of a failure of the internal staging server, this was a bit trickier. It could be restored from backups, but those would only be
as recent as the night before. In a worst case situation, the files would be copied back down from the external staging server, or even a
web server. There was once a filesystem failure with ReiserFS that forced this to be done.
This system worked perfectly for years, only with the occasional complaint, usually user failure. (i.e., a complaint of "My file isn't there",
where the user actually named the file something other than what they thought.)